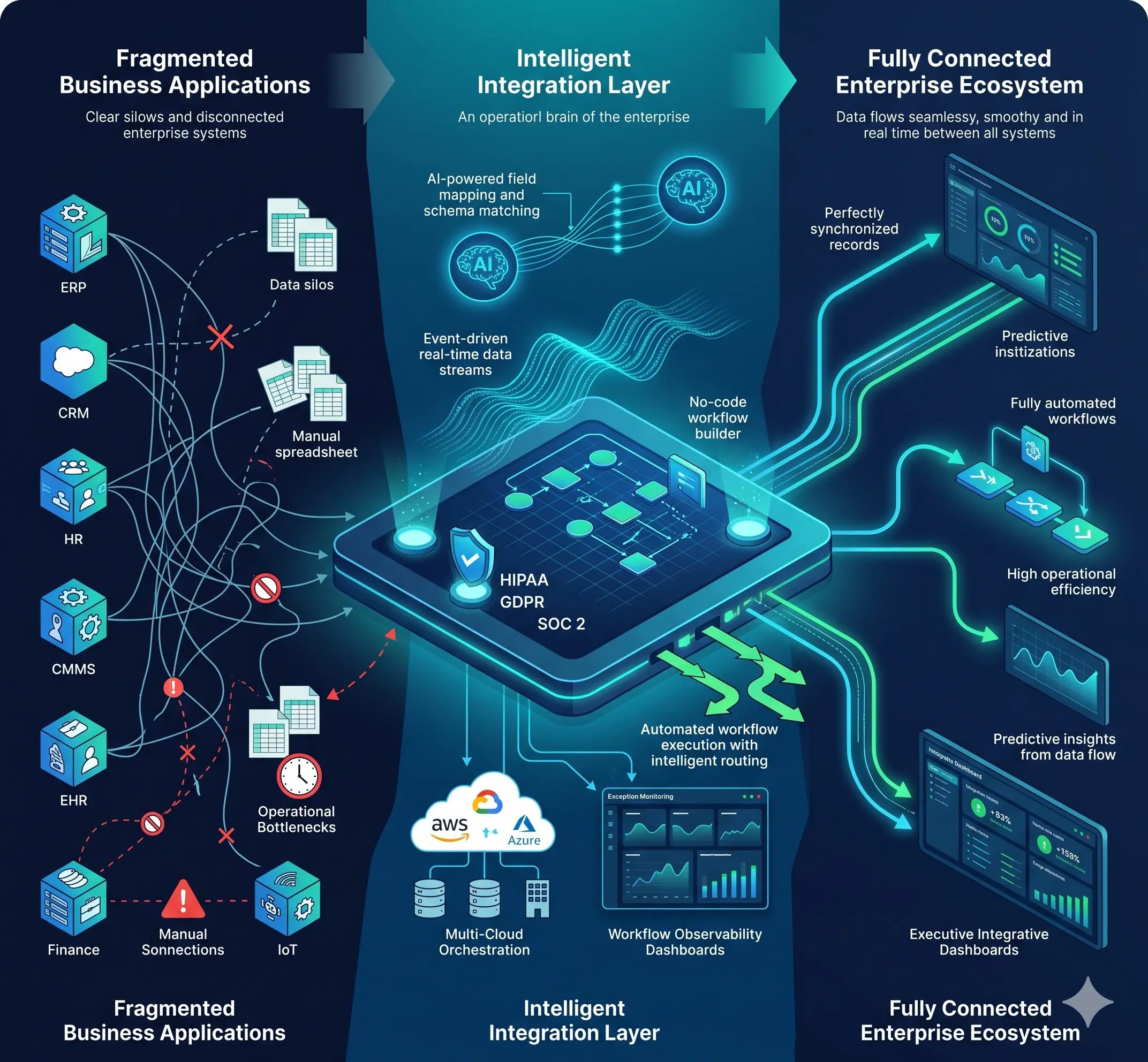
Business processes have become increasingly interconnected, but enterprise systems often remain isolated. Enterprises can orchestrate reliable multi-step workflows spanning ERP, CRM, and HR systems by steering away from ‘point-to-point' connections and toward a centralized integrated framework with the layer acting as the ‘brain’ to manage data flow and operations, keeping the need for human intervention to the minimum.
It becomes a more fundamental rethink of how data is allowed to move between systems in the first place: a visual integration platform that both business and technical teams can reason about, paired with an automated workflow builder that removes manual handoffs as a recurring point of failure. And more trends tend to follow that rewire the way enterprise workflows will evolve for the times ahead.
A lot is changing, but seven shifts are driving most of the momentum. Let’s have a quick look at each of them.
Trend 1: AI Is Not Just Automating Workflows. It Is Rewriting the Rules of Mapping.
The first of those shifts starts with mapping, the oldest and most tedious source of integration overhead. For years, integration work meant a developer opening two schemas side by side and manually deciding that "cust_id" in one system corresponds to "CustomerNumber" in another.
That manual work is where most implementation time and ongoing maintenance cost have always gone. Schemas change. Fields get renamed. Every change ripples through every connection that depends on it.
Machine learning models trained on large volumes of historical mapping patterns can now suggest correct field correspondences automatically. They flag likely mismatches before those mismatches cause downstream errors, and they adjust when a source system changes its structure. That's a different capability than simple task automation; it changes who designs an integration and how long the design takes.
A data integration platform that's learned from prior mappings can do this in minutes, not days, proposing a working configuration on its own, so a reviewer just checks the logic instead of building it from scratch. The result: pre-built data connectors keep getting smarter instead of sitting there static.
For operations executives, the relevant question is no longer whether AI belongs in integration work. It's how much manual mapping effort they are still willing to pay for, once a model can do it faster and more consistently.
Trend 2: Why Event-Driven Architecture Is Becoming Operational Standard
Smarter mapping solves one bottleneck. It doesn't solve a second, more visible one: how quickly data moves once it's been mapped correctly. Most legacy integration was built around batch jobs.
That cadence made sense when operations moved at the speed of a business day. It just doesn't match how inventory, logistics, customer service, or financial operations work anymore. Instead of processing massive batches of data on a rigid schedule, modern systems essentially have to react to information in real-time.
Because of this need for speed, modern cloud integration now uses a central hub to constantly route messages between your tools, leaving the old method of scheduled, rigid updates in the past.
Apps can simply 'tune in' to a live stream of updates and act the exact second something changes. Hence, the operational benefit is straightforward. But the architectural shift is not. It requires looking into error handling, ordering guarantees, and how downstream systems recover when an event gets missed. Organizations that get this right are acting on it sooner, and in operational terms; that's usually the more valuable outcome of the two.
Trend 3: Point-to-Point Architecture Creates Compounding Technical Debt
Event-driven design also exposes a problem hiding underneath most integration estates: how those events get wired together. Point-to-point connections are the easiest integration decision to make and the hardest one to unwind later. Connecting System A directly to System B solves an immediate problem in days. That's why it's almost always the first choice when a team needs something to work quickly.
The trouble starts at the third, fourth, and tenth connection. The number of direct links between systems grows faster than the number of systems itself, and every schema change risks breaking a connection nobody documented.
Twenty years ago, the industry came up with an answer: ESB service (Enterprise Service Bus) architecture, a one-place hub that every application plugged into just once, instead of wiring up a separate connection to every other system out there. That cut down the number of connections, sure, but it created its own headache; the bus itself turned into a single point of failure, and getting anything changed meant slogging through a slow, bureaucratic process.
Modern orchestration platforms address the same underlying problem differently, by treating each application to application integration as a managed, observable flow rather than a private wire between two systems. Technical debt accumulates quietly under either model when integrations aren't centrally visible. What's changed is the tooling available to prevent it.
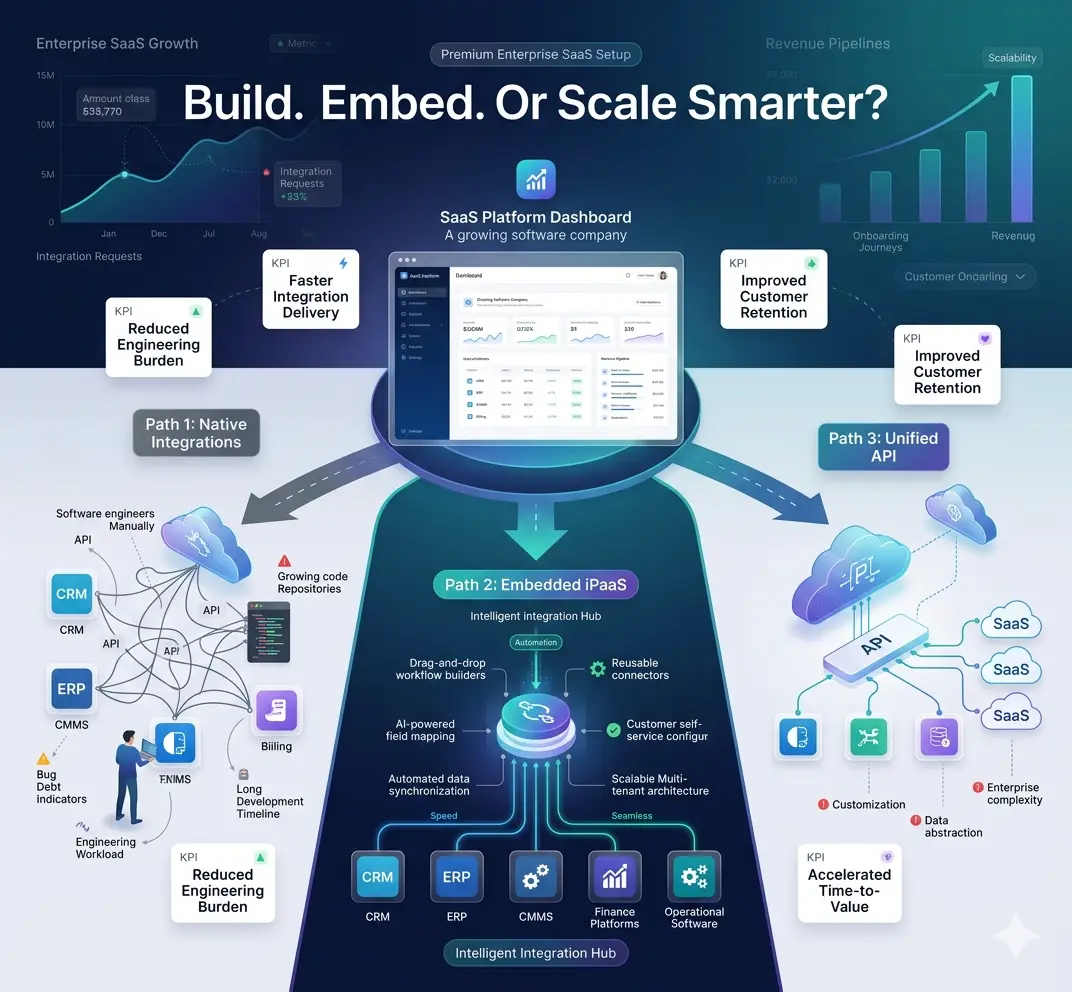
Trend 4: The No-Code Shift Is Not About Democratizing IT. It Is About Speed.
Solving the wiring problem with better tooling raises an obvious follow-on question: who builds these integrations, and how fast? The case for low-code and no-code integration tools is usually framed around access, letting non-developers build their own connections. That framing undersells the actual business driver.
Gartner has found that most new business applications, something like seven out of ten, now get built using low-code or no-code tools, nearly three times the share from just five years back. This has happened because the time between identifying an integration need and having it running in production has compressed from weeks to days, once configuration becomes visual rather than written.
A facilities or service operations team that needs mobile work order automation between a field technician's app and a back-office system cannot wait on a development sprint. Increasingly, they don't have to. Speed, not democratization, is the actual return on investment here.
The access story is true as a side effect; more people can participate in building integrations. But the reason finance approves these projects is simpler: an automated business process that used to take a quarter to deploy can now go live before the underlying business problem changes shape entirely.
Trend 5: Security Has Moved from IT Requirement to Integration Architecture Principle
Speed has a natural tension with another priority climbing every CIO's list: security. Security used to show up last in the integration conversation something that came at the bottom of a checklist once the connections were already up and running. Encrypt the data in transit, sure. Lock down who actually gets to see the credentials. Log who accessed what.
That sequencing doesn't hold up anymore. GDPR, HIPPA, and other regulations demand that companies prove their data handling practices through actual proof instead of just claiming them, and the volume of sensitive data moving between systems has grown faster than ad hoc security reviews can keep pace with.
From a practical perspective, role-based access control, field-level encryption, and auditable systems which used to be considered only after the process of complying with regulations was complete can now be part of the initial design of the integration architecture.
In general, an enterprise integration platform that considers security as an integral part of the system does much better during procurement processes. Buyers increasingly ask pointed questions about data residency, credential storage, and breach response before they ask about throughput.
This isn't a defensive trend confined to regulated sectors. It's becoming a primary criterion executive across industries to use to eliminate vendors before evaluating anything else about the platform.
Trend 6: The Multi-Cloud Reality Is Creating New Orchestration Complexity
Security gets harder still once those systems stop living in one place. Few organizations made a deliberate decision to run multi-cloud. It happened gradually: one business unit adopted AWS for a specific workload, another stayed on Azure because of an existing Microsoft relationship, and a third kept critical systems on premises for reasons that made sense at the time.
The result is an operational reality where data has to move not just between applications, but across infrastructure boundaries through API integration. Coordinating dozens of such integrations across distributed, integrated platform services requires visibility into dependencies spanning more than one provider's monitoring tools.
When something fails in this environment, the failure often surfaces in a system that had nothing to do with causing it, which makes workflow exception management considerably harder than it is in a single-cloud setup.
The organizations handling this well are putting their money into an orchestration layer that sits above any individual cloud provider basically one place where ops teams can see how a process flowed from start to finish, no matter which infrastructure each step happened to touch along the way.
Trend 7: Observability Is the New SLA. If You Cannot See It, You Cannot Manage It
That single vantage point is really what the last trend is about: seeing failure before it becomes a customer's problem. An integration that works most of the time but fails silently some of the time is, from an operational standpoint, worse than one that fails loudly and consistently.
Silent failure is the real cost driver in integration environments. The gap between a sync breaking and someone noticing is exactly where bad data quietly propagates into reports, invoices, and customer records that everyone downstream assumes are correct.
Observability addresses this directly. It comes down to knowing whether your data went through cleanly, how long it took, and what broke when it didn't, ideally catching that before a customer ever must call, not after. An integration monitoring dashboard that can identify failures, re-attempts, and high latencies makes integration health quantifiable, in the way that uptime did when it was recognized as an important metric many years ago. Executives evaluating integration vendors are increasingly asking for this visibility upfront, treating it as a baseline requirement.
ConnectorHub: The Integration Platform Built for What's Coming Next
These seven shifts aren't abstract market commentary. They are the design requirements behind how ConnectorHub approaches integration today. The platform's AI-assisted field mapping and anomaly detection address the mapping burden directly, flagging likely errors before they reach a downstream system rather than after.
ConnectorHub updates your work orders, asset records, and financial postings the moment something happens whether you are working in a CMMS, an ERP, a CRM, or an EHR. And you are not stuck building a fresh connection from scratch every time a new system joins the mix. ConnectorHub ships with a whole library of connectors already built and ready to go, so plugging in another application doesn't mean redoing all your integration work from square one.
Role-based access control, encrypted credentials, and audit logging are built into the platform right from day one, designed to line up with SOC 2, HIPAA, and GDPR instead of getting bolted on later. Moreover, the platform doesn't lock you into one cloud provider, and its live dashboards show SLA performance and exception rates in real time.
Also Read: How Integration Platforms Help Enterprise Teams Scale Without Adding Headcount?
Conclusion
Whichever platform an organization eventually chooses, a few practical starting points apply across all seven trends. Start with an audit. How many of your current integrations are still point-to-point connections with no central visibility? That number predicts how much technical debt you are carrying, whether or not it has caused an incident yet.
Ask any integration vendor to demonstrate monitoring and exception-handling capabilities before discussing connector count or pricing. Visibility after deployment matters more than breadth of supported applications on a feature sheet.
Treat security and compliance architecture as a procurement requirement from the first conversation, not a question reserved for legal review near the end. And if your teams are still waiting on development cycles to stand-up routine integrations, recognize that delay for what it is: a competitive disadvantage, not an acceptable cost of doing business.
None of this requires replacing every system currently in production. It requires deciding how data moves between those systems deserves the same scrutiny already applied to the systems themselves.
Facility management firms, healthcare networks, real estate operators, and service providers all run materially different operations. But they all need data to move effortlessly between business-critical applications without creating new operational bottlenecks every time a system changes, and the success for that depends on a scalable integration as a service approach. See how ConnectorHub can help future-proof your integration ecosystem by enabling exactly that.



.svg)